
MODELO DE ARQUITECTURA PIPELINE
Índice
ARQUITECTURA PIPELINE
El modelo Pipeline se denomina en el mundo de la informática a una serie de elementos de procesamiento de datos ordenados de tal modo que la salida de cada uno es la entrada del siguiente. Pipeline (tuberías en español) hace referencia a su nombre, básicamente es como el agua pasa por la tubería, donde el agua es la información o los procesos.
A continuación, explicaremos como funciona este modelo:
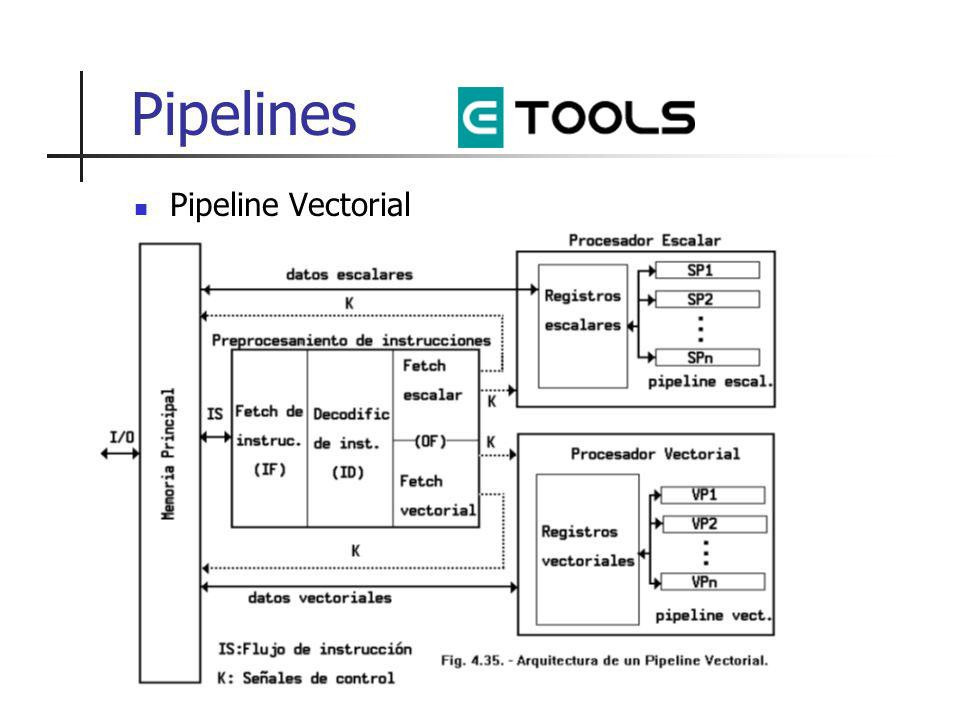
Modelo de Pipeline
La arquitectura Pipeline consiste en ir transformando un flujo de datos en un proceso comprendido por varias fases secuenciales, siendo la entrada de cada una la salida de la anterior, con un almacenamiento temporal de datos entre procesos.
Entender cómo funciona un pipeline es un paso importante para entender qué ocurre dentro de un procesador. Este sistema es común verlo en sistemas operativos multitarea ya que puede ejecutar una serie de procesos de manera simultánea, los cuales son ejecutados de manera secuencial mediante un administrador de tareas que aplica distintos tipos de prioridad y capacidad de procesamiento. Aquí se alterna entre este sistema (el de tuberías) y los demás.
Aplicación de pipelines en la informática
Los pipelines gráficos se encuentran en la mayoría de las tarjetas graficadoras y consiste en múltiples unidades aritméticas o CPUs completas que implementan distintos tipos de escenarios de operaciones típicas, como por ejemplo cálculos de luz.
En los que es software consiste en varios procesos ordenados de tal manera que el flujo de salida alimenta un proceso de entrada del siguiente proceso, como lo leímos anteriormente. Un ejemplo claro son los pipelines de Unix, que los procesos de este sistema se inicial al mismo tiempo.
Un aspecto a tener en cuenta de sistema pipelin es el concepto de almacenamiento en búfer: por ejemplo, un programa que envía datos puede producir 5.000 bytes por segundo, y un programa de recepción sólo puede ser capaz de aceptar 100 bytes por segundo pero los datos no se pierden nunca.
Si el buffer de la cola se llena, el programa que envía los datos se suspende/bloquea hasta que el programa receptor tiene la oportunidad de leer algunos datos y liberar espacio en el búfer.
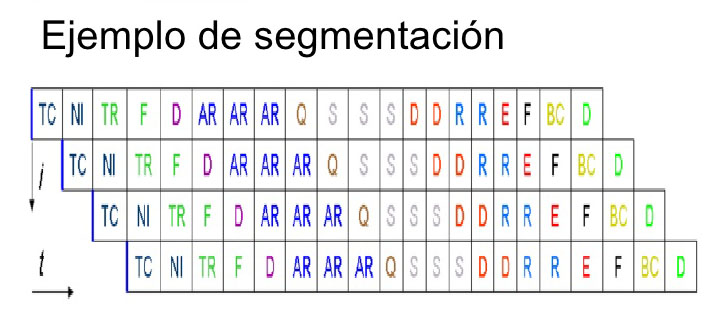
Ciclo de vida de una instrucción
La acción básica de cualquier microprocesador, en tanto se mueva a través de la corriente de instrucciones, se puede descomponer en 4 pasos, que cada instrucción en la corriente de código se debe atravesar para poder ejecutarse con éxito:
- Fetch: se encarga de “traer” la instrucción que se debe ejecutar, de la dirección que está almacenada en el contador del programa.
- Store: se encarga de “guardar o almacenar” la instrucción en el registro de instrucciones y luego “descifrarla”, incrementando la dirección en el contador de programa.
- Execute: se ejecuta la instrucción almacenada en el registro de instrucciones. Si la instrucción no es un instrucción de rama si no una instrucción aritmética, este proceso la envía la ALU donde el microprocesador “lee” el contenido de los registros de entrada y “agrega” el contenido de los registros de entrada.
- Write: “escribe” los resultados de esa instrucción dentro del registro de destinación.
En un proceso moderno, los cuatro pasos son repetidos una y otra vez hasta que el programa termine de ejecutarse.
Consumo en la arquitectura Pipeline
Para poder reducir el consumo que se produce, se investigan unas series de soluciones de compromiso entre la resolución por etapa y la cantidad de etapas.
Estos poseen un método de escalamiento de capacitores que está descripto para reducir la potencia con el cual se ha sobredimensionado en las últimas etapas del caso de una arquitectura Pipeline convencional. También está el uso de la corrección digital que permite eliminar los efectos no deseados causados por imperfecciones de los comparadores utilizando circuitos digitales de bajo consumo y de bajo costo.
Características de pipeline
Dentro del Pipeline se puede hablar de niveles de paralelismo que son caracterizados de la siguiente manera:
- Multiprogramación y Multiprocesamiento: Estas acciones se toman a un nivel de Programa o Trabajo.
- Tarea o Procedimientos: Acciones que se toman dentro de un mismo programa ejecutándose procesos que son independientes de manera simultánea.
- Interinstrucciones: Acciones a nivel de instrucción, o sea dentro del mismo proceso o tarea sé que se pueden ejecutar instrucciones independientes de manera simultánea.
Conclusiones
Las tuberías virtuales se crean para segmentar los datos y de este modo incrementar su rendimiento de un sistema digital.
El Pipeline es común verlo en sistemas multitarea, como los que empleamos hoy en día en nuestras computadoras; se ejecutan una serie de procesos de manera simultánea, que son ejecutados luego de manera secuencial mediante un administrador de tareas dándole diferente prioridad y capacidad de procesamiento, alternando entre un pipeline y los demás hemos dedicado por tener que familiarizarnos con el entorno de desarrollo por primera vez.
¡Si te gustó este artículo no dudes en dejarnos un comentario aquí abajo!
Si quieres conocer otros artículos parecidos a MODELO DE ARQUITECTURA PIPELINE puedes visitar la categoría Electrónica digital.
OPERACIONES CON NÚMEROS HEXADECIMALES
Sistema Hexadecimal

CONVERSIÓN DE DECIMAL CON DECIMALES A BINARIO

SISTEMA BINARIO
COMPUERTAS LÓGICAS
SEÑALES ANALÓGICAS Y DIGITALES
Subir
Deja un comentario